The search for genetic
material led to DNA
_ Until the 1940s, the great variety of proteins
seemed to indicate that proteins were the genetic material.
_ The discovery of the genetic role of DNA began
with research by Griffith in 1928.
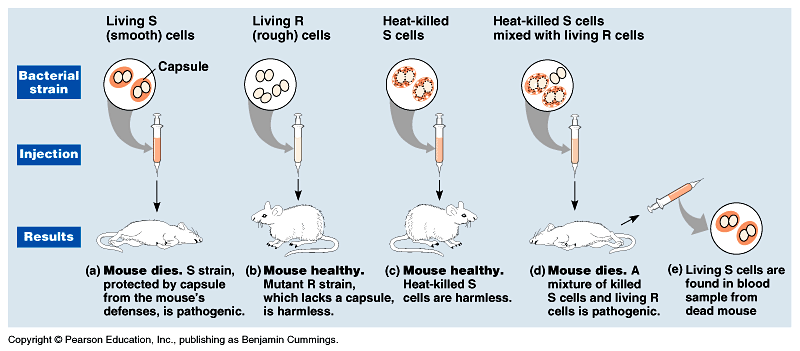
_ He studied Streptococcus pneumoniae, a bacterium
that causes pneumonia in mammals. Fig
16.1.
_ the R strain, was harmless.
_ the S strain, was pathogenic.
_ Griffith
mixed heat-killed S strain with live R strain bacteria and injected
this into a mouse.
_ The mouse died and he recovered the pathogenic
strain from the mouse's blood.
_ Griffith called this phenomenon transformation,
a change in genotype and phenotype due to the assimilation of
a foreign substance (now known to be DNA) by a cell.
_ In 1944, Avery, McCarty and MacLeod, after years of experiments with bacteria, announced that the transforming substance was DNA. Many were still skeptical.
_ Further
evidence that DNA was the genetic material was derived from studies
that tracked the infection of bacteria by viruses.
_ Viruses consist of a DNA molecule (sometimes
RNA) enclosed by a protective coat of protein.
_ To replicate, a virus infects a host cell and takes
over the cell's metabolic machinery. Movie!
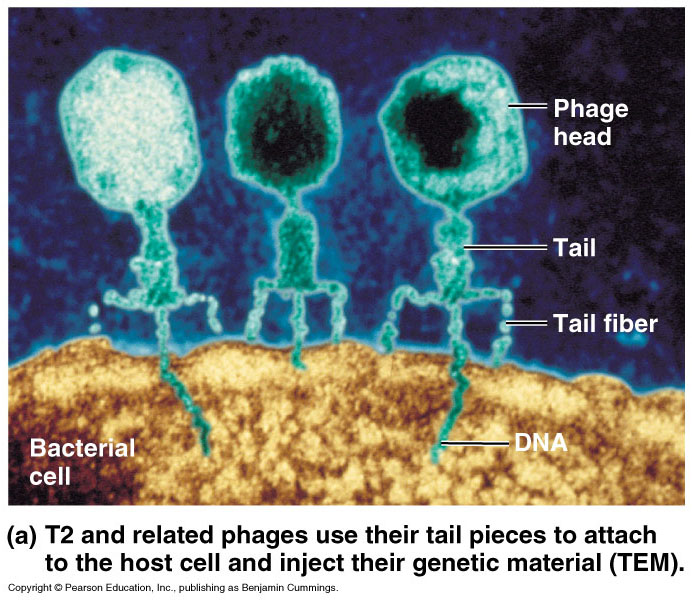
_ Viruses
that specifically attack bacteria are called bacteriophages
or just phages. Fig
16.2a
_ In
1952, Hershey and Chase showed that DNA was the genetic
material of the phage T2. Fig
16.2b
_ To
determine the source of genetic material in the phage, Hershey
and Chase designed an experiment where they could label protein
or DNA and then track which entered the E. coli cell during
infection.
_ They grew one batch of T2 phage in the presence of radioactive sulfur, marking the proteins but not DNA.
_ They grew another batch in the presence of radioactive phosphorus, marking the DNA but not proteins.
_ They allowed each batch to infect separate E. coli cultures.
_ They spun the cultured infected cells in a blender, shaking loose any parts of the phage that remained outside the bacteria.
_ The mixtures were spun in a centrifuge which separated the heavier bacterial cells in the pellet from lighter free phages and parts of phage in the liquid supernatant.
_ Hershey and Chase found that when the bacteria had been infected with T2 phages that contained radio-labeled proteins, most of the radioactivity was in the supernatant, not in the pellet.
_ When they examined the bacterial cultures with T2 phage that had radio-labeled DNA, most of the radioactivity was in the pellet with the bacteria.
_ Hershey and Chase concluded that the injected DNA of the phage provides the genetic information that makes the infected cells produce new viral DNA and proteins, which assemble into new viruses.
_ Other evidence - cells
double the amount of DNA in a cell prior to mitosis and then distribute
the DNA equally to each daughter cell.
_ Diploid sets of chromosomes have twice as much DNA as the haploid
sets in gametes of the same organism.
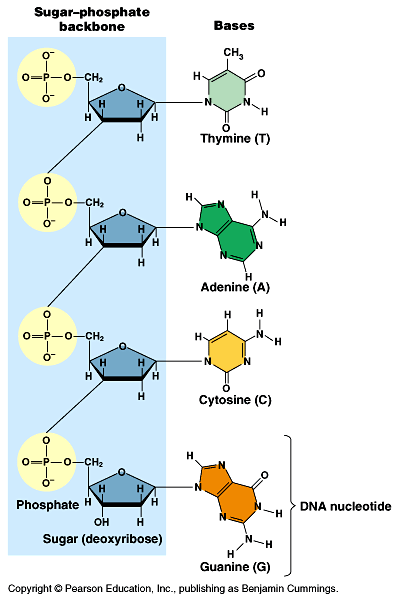
_ By 1947, Chargaff had developed a series of rules based on a survey of DNA composition in organisms.
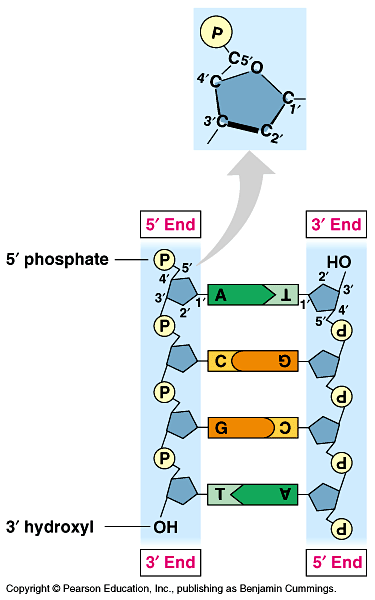
_ He already knew that DNA was a polymer of nucleotides consisting of a nitrogenous base, deoxyribose, and a phosphate group. Fig 16.3
_ The bases could be adenine (A), thymine (T), guanine (G), or cytosine (C).
_ Chargaff noted that the DNA composition varies from species to species.
_ In any one species, the four bases are found in characteristic, but not necessarily equal, ratios.
_ He also found a regularity in the ratios of nucleotide bases which are known as Chargaff's rules.
_ The number of adenines was approximately equal to the number of thymines (%T = %A).
_ The number of guanines was approximately equal to the number of cytosines (%G = %C).
_ Human DNA is 30.9% adenine, 29.4% thymine, 19.9% guanine and 19.8% cytosine.
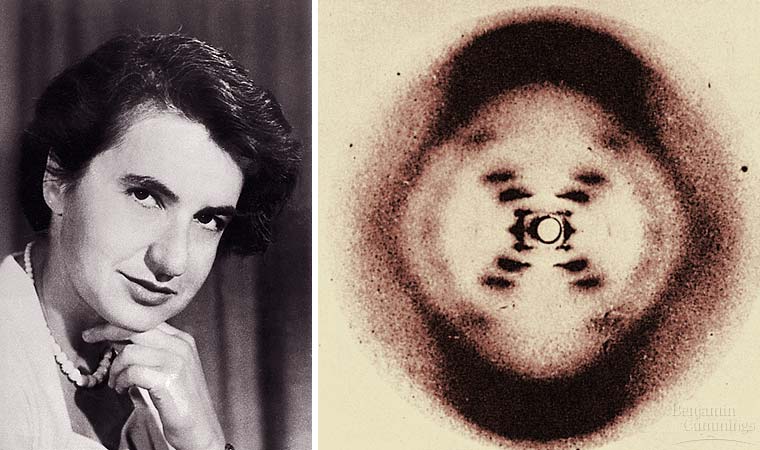
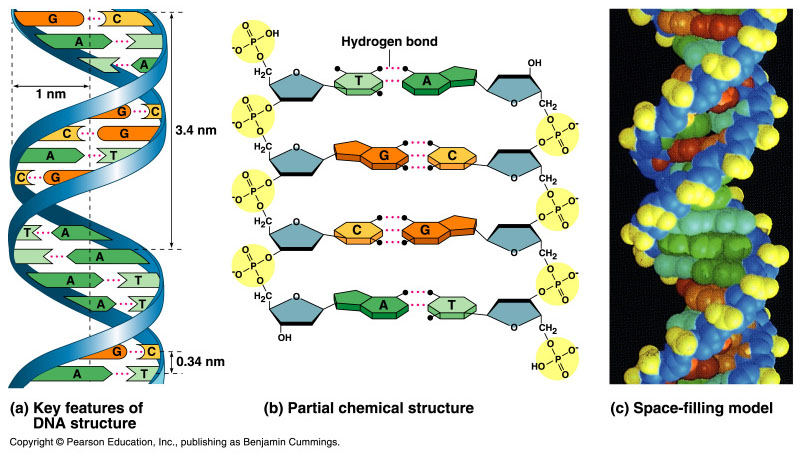
_ Wilkins and Franklin used X-ray crystallography to study the structure of DNA. Fig 16.4
_ Watson
and Crick, building on the work of Wilkins and Franklin,
began to work on a model of DNA with two strands, the double helix.
Fig
16.5.
_ The key breakthrough came when Watson put the sugar-phosphate
chain on the outside and the nitrogen bases on the inside of the
double helix.
_ The sugar-phosphate chains of each strand are like the side ropes of a rope ladder.
_ Pairs of nitrogen bases, one from each strand, form rungs.
_ The ladder forms a twist every ten bases.
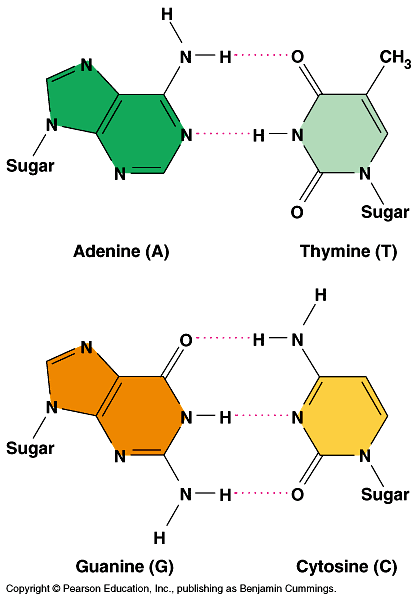
_ The nitrogenous bases are paired in specific combinations: adenine with thymine and guanine with cytosine.
_ Pairing like nucleotides did not fit the uniform diameter indicated by the X-ray data.
_ A purine-purine pair would be too wide and a pyrimidine-pyrimidine pairing would be too short.
_ Only a pyrimidine-purine pairing would produce the 2-nm diameter indicated by the X-ray data.
_ In addition, Watson and Crick determined that chemical side groups of the nitrogen bases would form hydrogen bonds, connecting the two strands. Fig 16.6.
_ Based on details of their structure, adenine would form two hydrogen bonds only with thymine and guanine would form three hydrogen bonds only with cytosine.
_ This finding explained Chargaff's rules.
_ The linear sequence of the four bases can be varied in countless ways.
_ Each gene has a unique order of nitrogen bases.
DNA replication
_ In a second paper Watson and Crick published their hypothesis
for how DNA replicates.
A large variety of enzymes and other proteins carries out DNA replication
_ More than a dozen enzymes and other proteins participate in DNA replication.
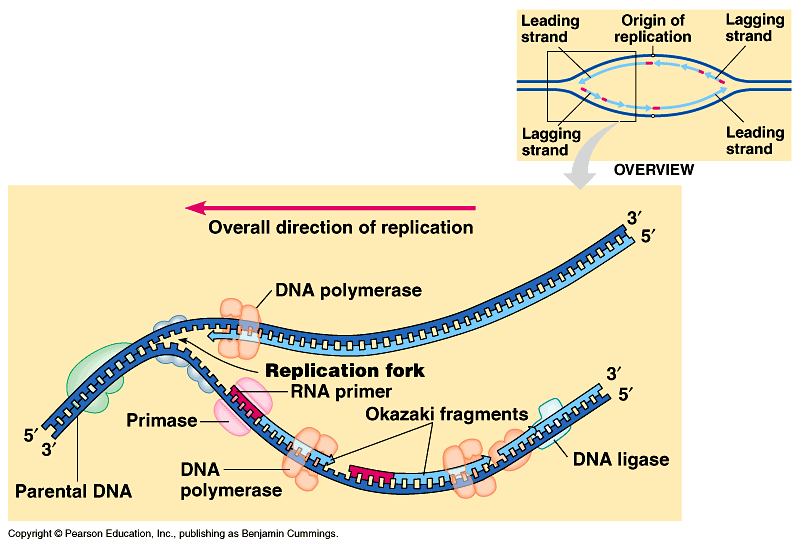
_ The replication of a DNA molecule begins at special sites, origins of replication. Fig 16.10. Movie!
_ In bacteria, this is a single specific sequence of nucleotides that is recognized by the replication enzymes.
_ These enzymes separate the strands, forming a replication "bubble".
_ Replication proceeds in both directions until the entire molecule is copied.
_ In eukaryotes, there may be hundreds or thousands of origin sites per chromosome.
_ At the origin sites, the DNA strands separate forming a replication "bubble" with replication forks at each end.
_ The replication bubbles elongate as the DNA is replicated and eventually fuse.
_ DNA polymerases catalyze the elongation of new DNA at a replication fork.
_ Nucleotides are added to the growing end of the new strand by the polymerase.
_ The raw nucleotides are nucleoside triphosphates.
_ The strands in the double helix are antiparallel. Fig 16.12.
To start a new chain requires
a primer, a short segment of RNA. Fig
16.14.
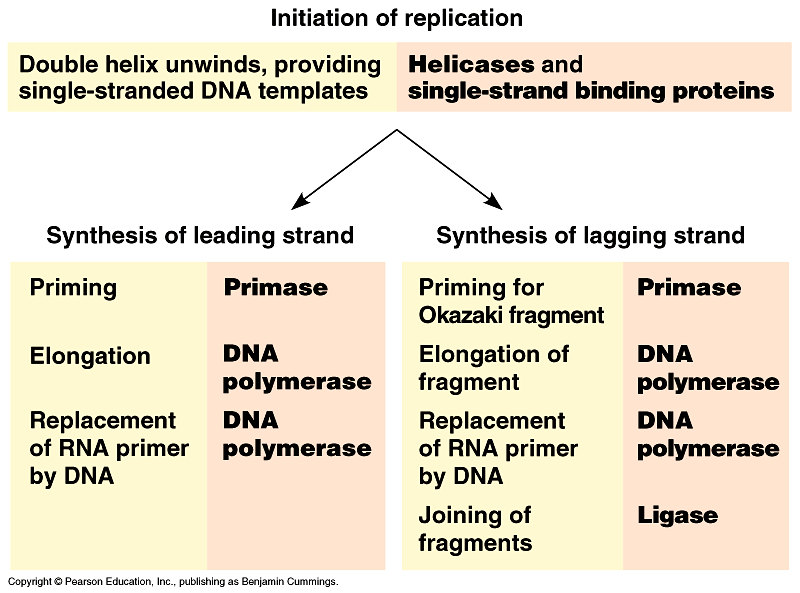
Summary of replication. Fig 16.16. Movie!
The main proteins of replication. Fig 16.15.
In addition to primase, DNA polymerases, and DNA ligases, several other proteins have prominent roles in DNA synthesis.
DNA polymerase proofreads each new nucleotide against the template nucleotide as soon as it is added.
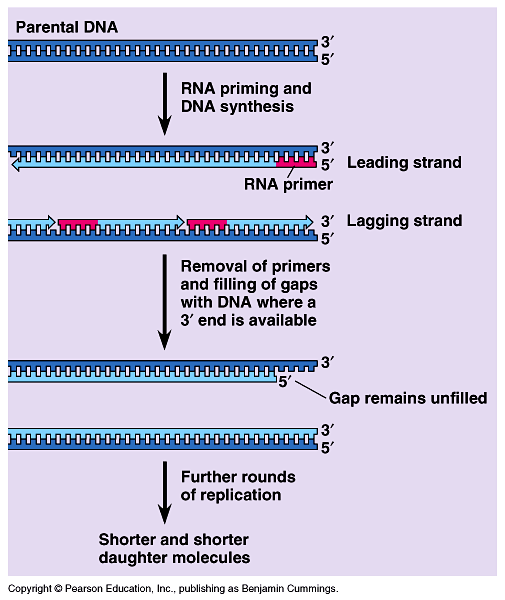
The ends of DNA molecules are replicated by a special mechanism. Fig 16.18.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}